感谢不蒜子让我们的静态站也能有访问量统计功能🙏
我一直想知道网站哪些内容受欢迎,我手工统计了一些,太麻烦。能不能自动化呢?下面是我的解决方案,工具是脚本+命令行工具。话说,有没有大佬能指导一下基于脚本的实现方法呢?我总是遇到安全性啊一类的东东,索性不基于浏览器的技术了。
2021-01-20 Update:
折腾了一下,用一个完整的脚本实现这个功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| pushd /tmp
wget https://chriszheng.science/page-sitemap.xml
wget https://chriszheng.science/post-sitemap.xml
xmllint --xpath '////*[local-name()="urlset"]/*[local-name()="url"]/*[local-name()="loc"]/text()' page-sitemap.xml > /tmp/url
xmllint --xpath '////*[local-name()="urlset"]/*[local-name()="url"]/*[local-name()="loc"]/text()' post-sitemap.xml >> /tmp/url
sort -u /tmp/url > /tmp/list
search()
{
echo ${1} >> /tmp/res
curl -H "Referer: ${1}" -X GET "http://busuanzi.ibruce.info/busuanzi?jsonpCallback=BusuanziCallback_1046609647591" >> /tmp/res
echo >> /tmp/res
sleep 1
}
export -f search
parallel -j 1 'search {}' :::: /tmp/list
awk '(NR%2) {printf("%s\t", $0)} (NR%2!=1) {system("cut -d: -f3 <<< \"" $0 "\"| cut -d, -f1")}' /tmp/res > /tmp/res-num
sort -k2nr /tmp/res-num | head -n20
|
制作要导出访问量的URL列表
我从sitemap里复制出来的。方法当然有很多了。
用cURL查询
这里为了让代码简单用了parallel软件:
1
2
3
4
5
6
7
8
9
10
11
| search()
{
echo ${1} >> /tmp/res
curl -H "Referer: ${1}" -X GET "http://busuanzi.ibruce.info/busuanzi?jsonpCallback=BusuanziCallback_1046609647591" >> /tmp/res
echo >> /tmp/res
sleep 1
}
export -f search
parallel -j 1 'search {}' :::: /tmp/list
|
数据处理
这样生成的数据类似这样
1
2
3
4
| https://chriszheng.science/2017/01/02/One-sentence-tips-on-software/
try{BusuanziCallback_1046609647591({"site_uv":48250,"page_pv":540,"version":2.4,"site_pv":92639});}catch(e){}
https://chriszheng.science/2018/11/30/Popularity-of-my-content/
try{BusuanziCallback_1046609647591({"site_uv":48251,"page_pv":67,"version":2.4,"site_pv":92640});}catch(e){}
|
还是用脚本搞定
1
| awk '(NR%2) {printf("%s\t", $0)} (NR%2!=1) {system("cut -d: -f3 <<< \"" $0 "\"| cut -d, -f1")}' /tmp/res > /tmp/res-num
|
注意里面转义的用法。
这样输出的是类似这样的
1
2
3
4
| https://chriszheng.science/2017/01/02/One-sentence-tips-on-software/ 540
https://chriszheng.science/2018/11/30/Popularity-of-my-content/ 67
https://chriszheng.science/2019/01/01/Recent-thoughts-2019-01-01/ 49
https://chriszheng.science/2019/01/07/Struggle-with-UEFI-GPT/ 36
|
然后排序就可以啦
1
| sort -k2nr /tmp/res-num | head -n20
|
这样可以输出访问量前20的文章。
统计分析
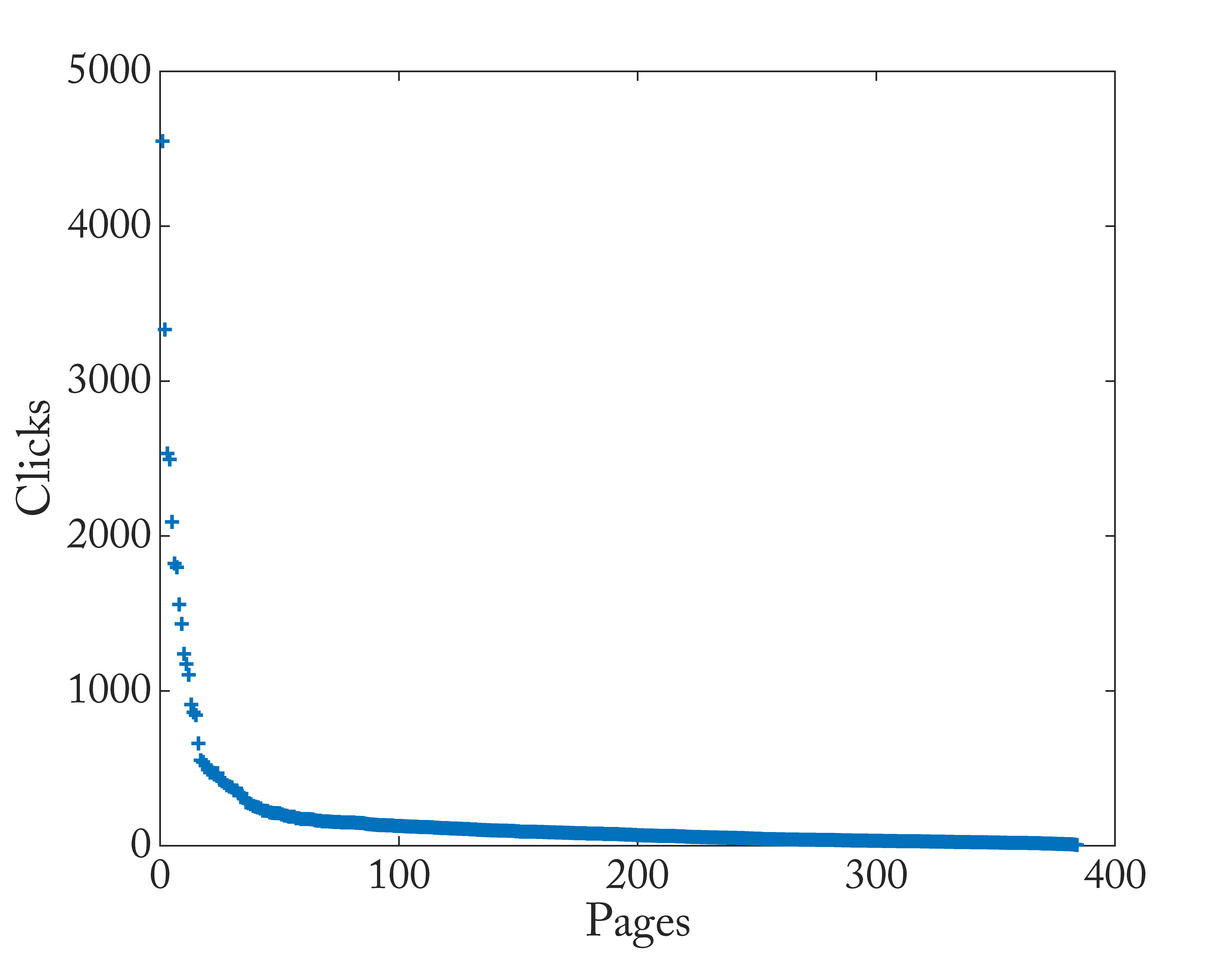
-
拐点在17,总访问量63920,前17篇文章的加合是28951 (占总数45%)。
-
248篇(64.5%)文章访问量低于100,这些文章贡献了11992 (18.8%)的访问量。
-
根据内容把前17篇文章归类,见下面的列表。
-
闲言碎语不容易获得关注。我写了很多脚本使用相关的,也少有人关注。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| # Emacs
https://chriszheng.science/2015/03/19/Chinese-version-of-Emacs-building-guideline/ 4549
https://chriszheng.science/2015/04/26/Emacs-font-settings/ 1822
https://chriszheng.science/2016/08/24/Why-Emacs-lags-when-display-Chinese-under-MS-Windows/ 1798
https://chriszheng.science/2017/07/16/Best-practice-of-Emacs-on-MS-Windows/ 1239
https://chriszheng.science/2017/07/20/Pomodoro-technique-using-Emacs/ 843
https://chriszheng.science/2018/02/08/Whats-new-in-Emacs-26/ 552
# 标记语言 也和Emacs有关
https://chriszheng.science/2015/11/08/Checkbox-for-markdown-mode/ 2090
https://chriszheng.science/2015/02/15/Comparision-between-Markdown-and-Org-mode/ 660
# Grammarly
https://chriszheng.science/2016/11/06/Grammarly-review/ 3333
# 蹭了热点
https://chriszheng.science/2016/02/07/Four-kings-in-Chinese-programming-world/ 2533
# 路由器、网络、VPS相关
https://chriszheng.science/2016/02/04/Play-with-ShadowSocks-on-PandoraBox-OpenWrt/ 2494
https://chriszheng.science/2015/01/21/Bandwagon-VPS-Nginx-setup/ 1557
https://chriszheng.science/2017/01/13/Use-Yaaw-in-HTTPS-environment/ 1432
https://chriszheng.science/2016/03/11/Shadowsocks-libev-one-time-auth/ 1173
https://chriszheng.science/2016/01/13/PandoraBox-switch-config/ 1104
https://chriszheng.science/2017/02/12/Dont-upgrade-to-shadowsocks-libev-3.0.x/ 861
# 编程和软件相关
https://chriszheng.science/2017/03/07/Remove-highlight-in-SumatraPDF/ 911
|
2021-01-20 Update:
又过了2年,把流程写成了一个脚本,重新统计了哪些内容受人喜欢。
在这个短视频当道、碎片化阅读时间的时代,还有人看文字的内容,是让人尊重的。上面这些都是2018年以前我写的东西了,那最近3年哪些内容受欢迎呢?
访问量低还是和内容产出数量质量少有关。
本文标题:导出不蒜子的访问量数据
文章作者:Chris
发布时间:2019-01-23
最后更新:2022-03-23
原始链接:https://chriszheng.science/2019/01/23/Export-busuanzi-data/
版权声明:本博客所有文章除特别声明外,均采用 CC BY 4.0 许可协议。转载请注明出处!